最近开始学习Raft算法,就简单记录一下吧。
(本文及后续相关文章的实现基于 MIT 6.824 Lab 2: Raft 2022 进行。)
背景知识
复制状态机
一组服务器上的状态机产生相同状态的副本,并且在一些机器宕掉的情况下也可以继续运行。复制状态机在分布式系统中被用于解决很多容错的问题。

图 1 :复制状态机的结构。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
状态机处理日志中相同顺序的命令序列,因此会输出相同的结果。
一般通过使用复制日志来实现复制状态机。保证复制日志的一致性是共识算法的任务。
一致性算法
用于管理来自客户端的状态机命令的复制日志,确保每一个日志最终包含相同的请求且顺序也相同。即上图中的log
实际系统中使用的一致性算法通常含有以下特性:
- 安全性保证(绝对不会返回一个错误的结果):在非拜占庭错误情况下,包括网络延迟、分区、丢包、重复和乱序等错误都可以保证正确。
- 可用性:集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用。因此,一个典型的包含 5 个节点的集群可以容忍两个节点的失败。服务器被停止就认为是失败。它们稍后可能会从可靠存储的状态中恢复并重新加入集群。
- 不依赖时序来保证一致性:物理时钟错误或者极端的消息延迟只有在最坏情况下才会导致可用性问题。
- 通常情况下,一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能。
Raft简介&基础
Raft算法是一种应用在分布式系统中,让所有节点对同一份数据的认知能够达成一致的“共识”算法,以保证集群数据在部分节点故障、网络延时、网络分割等异常条件下也具有一致性,提高分布式系统的容错性。
Raft算法试图将复杂的一致性问题分解为多个子问题,以此来降低算法的理解门槛和实现难度。分解后的子问题包括:
- Leader选举(Leader Election)
- 日志同步(Log Replication)
- 安全性(Safety)
- 日志压缩(Log Compaction)
- 成员变更(Membership Change)
进一步说,Raft的核心实际上就是解决Leader选举和日志同步两个子问题,实现这两个子问题后,Raft即可在集群中正常运行,其他子问题是在极端情况下,对这两个子问题进行的补充。
服务器状态
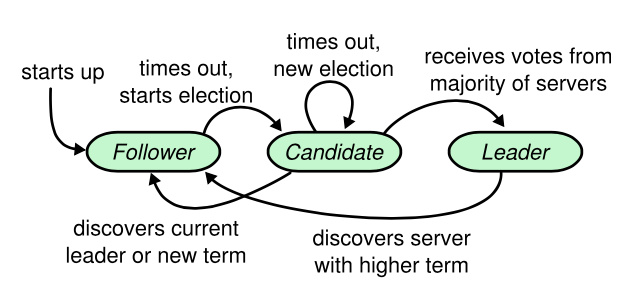
Raft服务器存在以下三中状态:
- 追随者(
Follower) :服务器初始化状态。不发送任何请求,只是响应来自Leader和Candidate的请求。不实际处理客户端请求,如果收到客户端请求会转发给Leader处理。如果Follower在超时时间内,没有收到任何消息,会转换状态为Candidate,并开始一次选举。 - 领导人(
Leader):处理所有来自客户端的请求(如果一个客户端与Follower进行通信,Follower将信息转发给Leader)。 - 候选人(
Candidate): 选举Leader时的状态
这三种状态的转换关系如图:
任期
在Raft中,时间被划分成一个个的任期,每个任期始于一次选举。在选举成功后,领导人会管理整个集群直到任期结束。有时候选举会失败,那么这个任期就会没有领导人而结束。任期之间的切换可以在不同的时间不同的服务器上观察到。
- 如果当前节点的任期号比其它节点的小,则更新为较大的任期号。
- 如果一个
Candidate或者Leader意识到它的任期比其他服务器任期小,则立刻转换为Follower状态。

RPC请求
Raft中的服务器通过远程过程调用(RPC)来通信,基本的 Raft 共识算法仅需要 2 种 RPC。
RequestVote RPC是Candidate在选举过程中触发的,AppendEntries RPC是Leader触发的,用来复制日志条目和提供一种心跳(空请求)机制。
Leader选举
Leader状态保持
Raft 使用一种心跳机制来触发Leader选举。一个服务器节点继续保持着Follower状态只要他从Leader或者Candidate处接收到有效的 RPC 请求。Leader周期性的向所有Follower发送心跳包(即不包含日志项内容的AppendEntries RPC)来维持自己的权威。如果一个Follower在一段时间里没有接收到任何消息,也就是选举超时(election timeout),那么他就会认为系统中没有可用的Leader,并且发起选举以选出新的Leader。
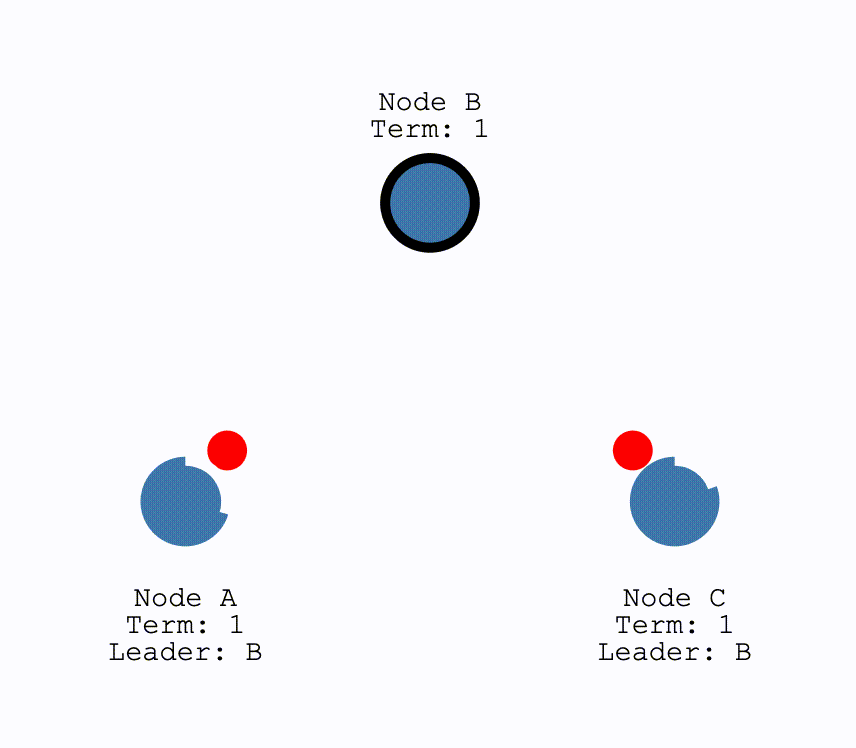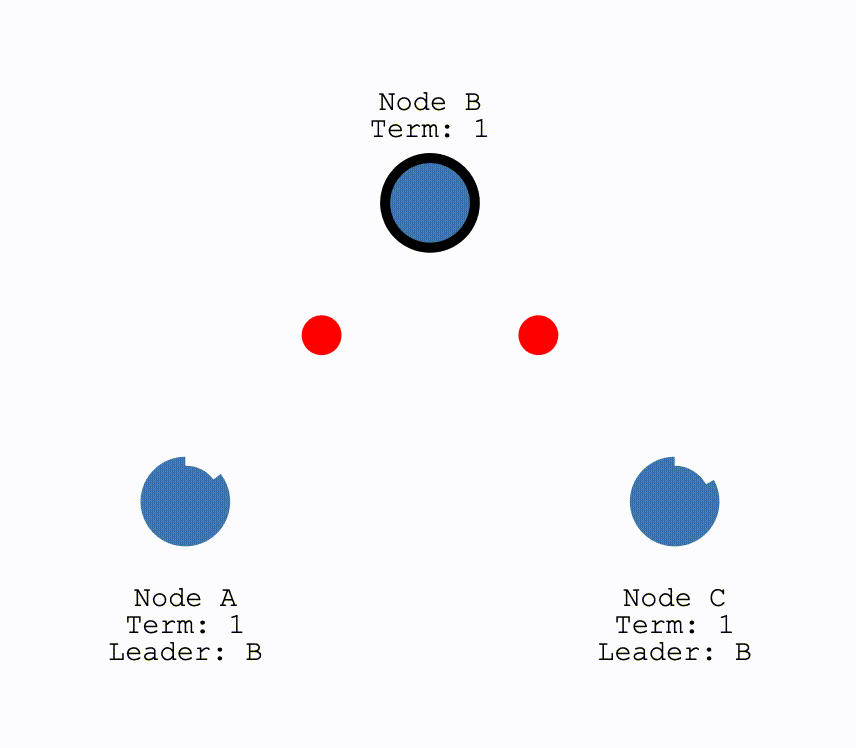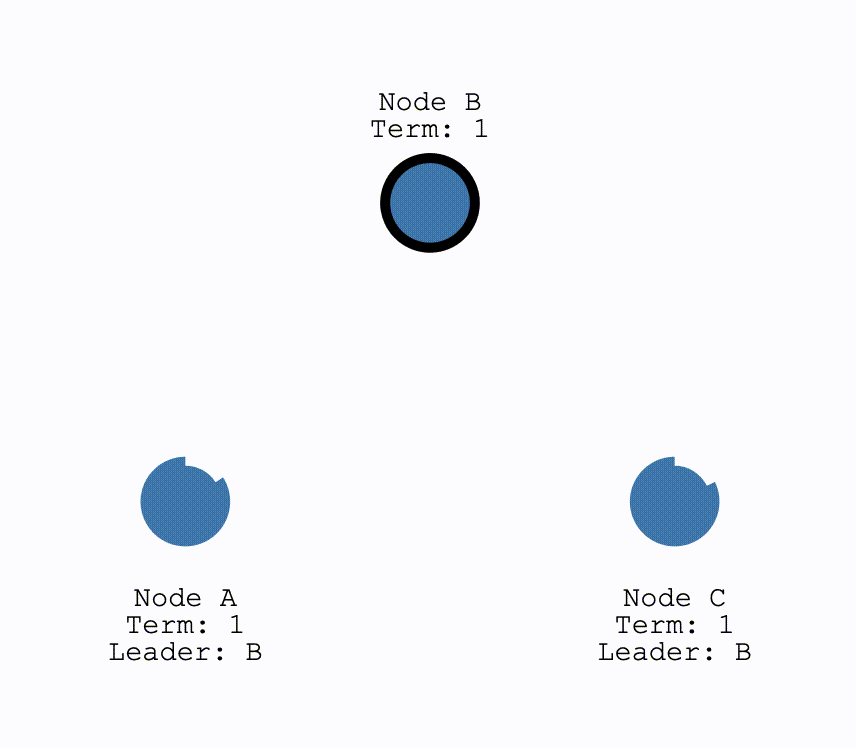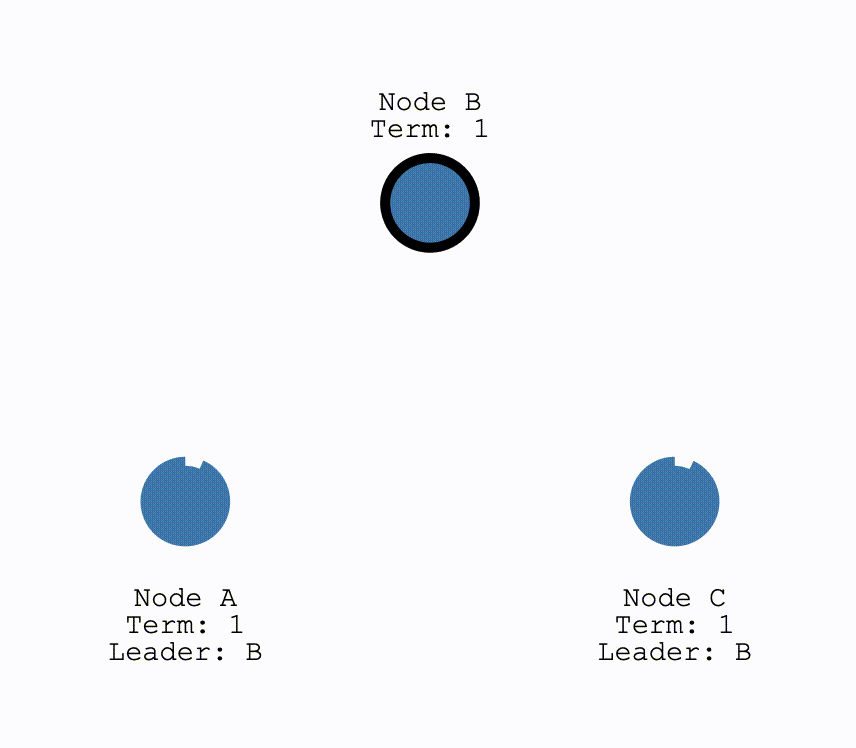
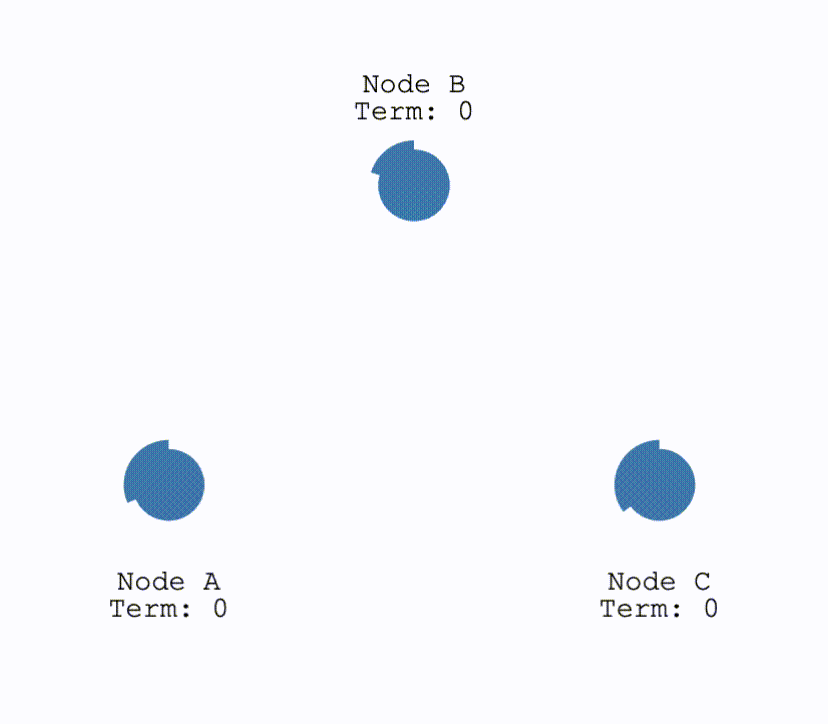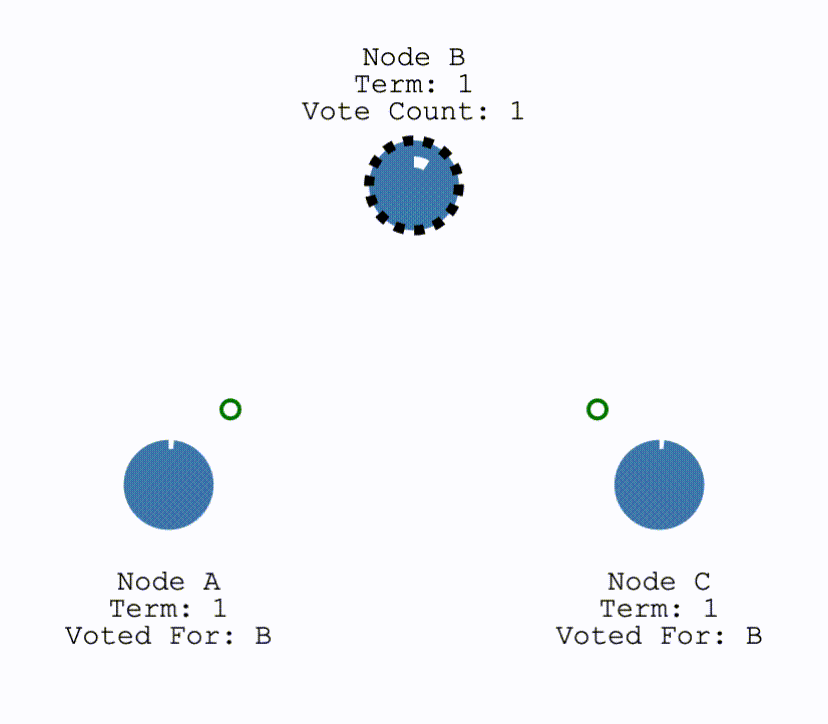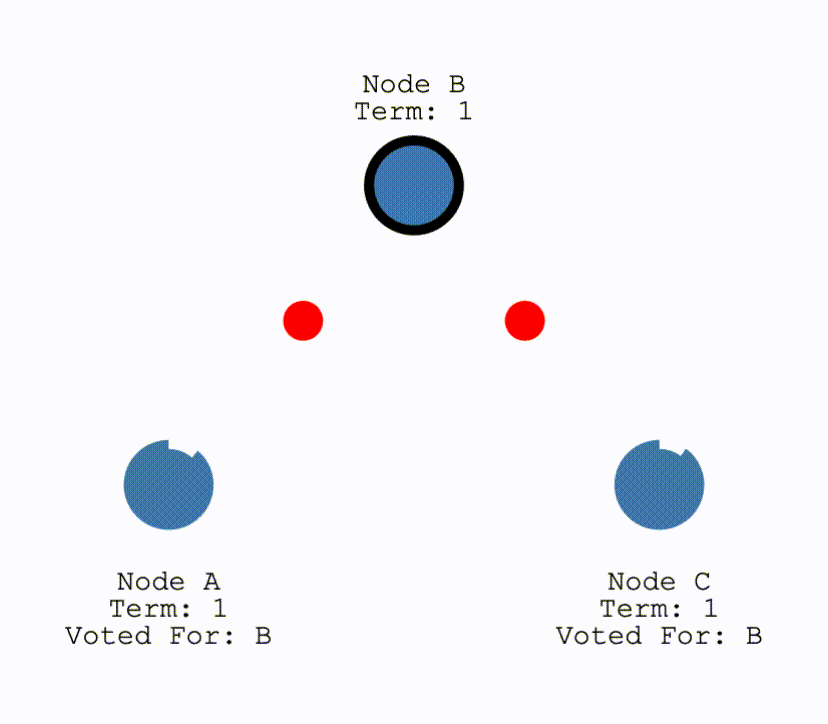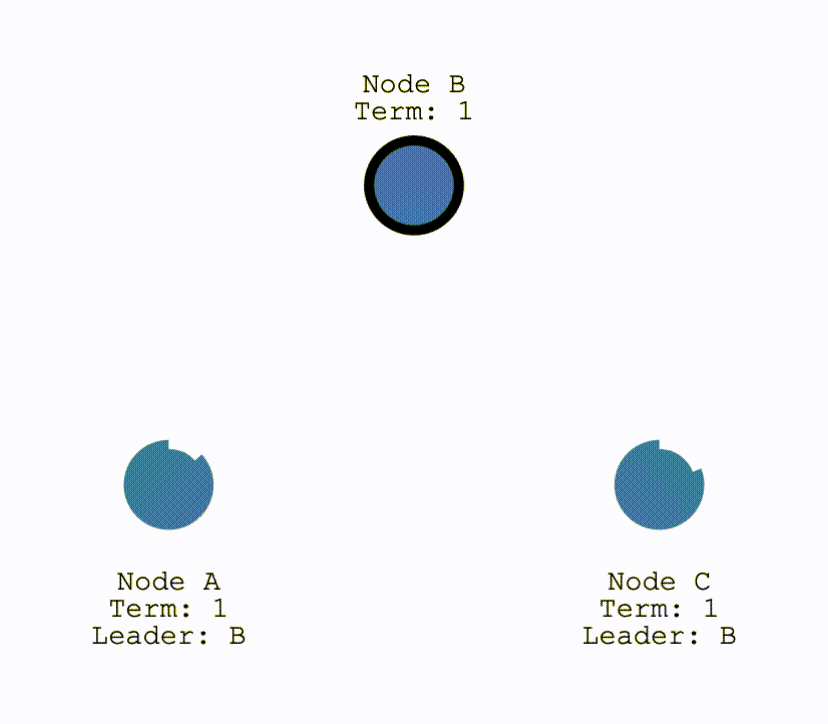
初次选举
在初始时,所有节点都为Follower,当有节点超时,成为Candiate后结点会向所有其他结点发送请求投票的请求(RequestVote),其他结点在收到请求后会判断是否可以投给他并返回结果。Candidate 如果收到了半数以上的投票就可以成为 Leader,成为之后会立即并在任期内定期发送一个心跳信息通知其他所有结点新的 Leader 信息,并用来重置定时器,避免其他结点再次成为 Candidate。
如果 Candidate 在一定时间内没有获得足够的投票,那么就会进行一轮新的选举,直到其成为 Leader,或者其他结点成为了新的 Leader,自己变成 Follower。
再次选举
以下情况会导致再次选举:
Leader下线- 网络通信发生问题,导致出现分区
对于Leader下线的情况,此时所有其他结点的计时器不会被重置,直到一个结点成为了Candidate,并开始新的一轮选举,选出新的Leader:
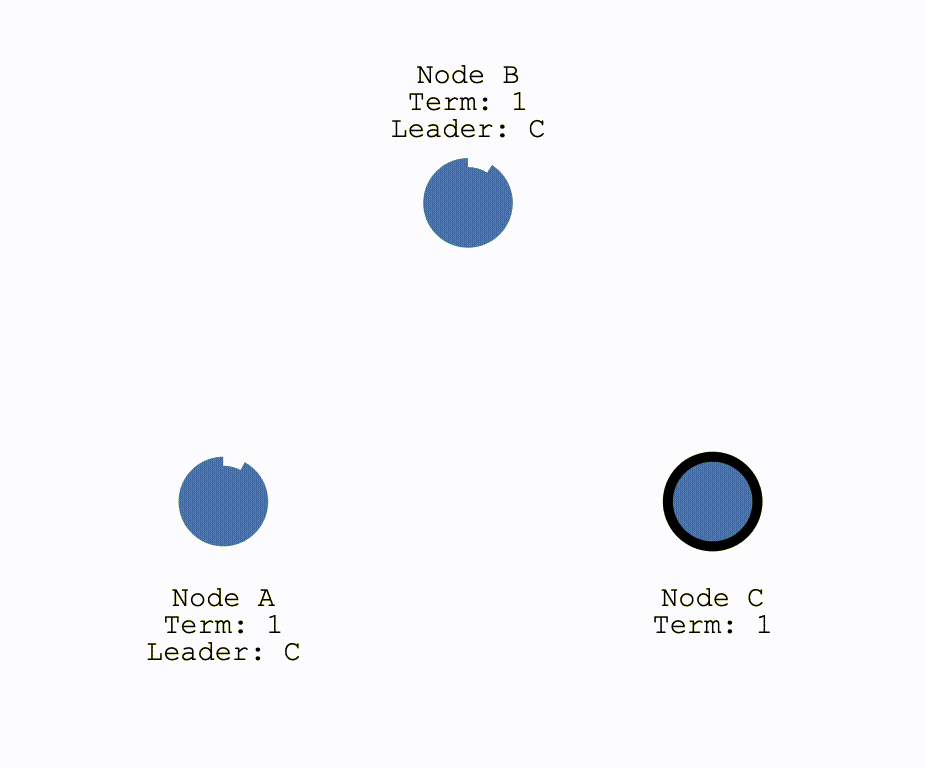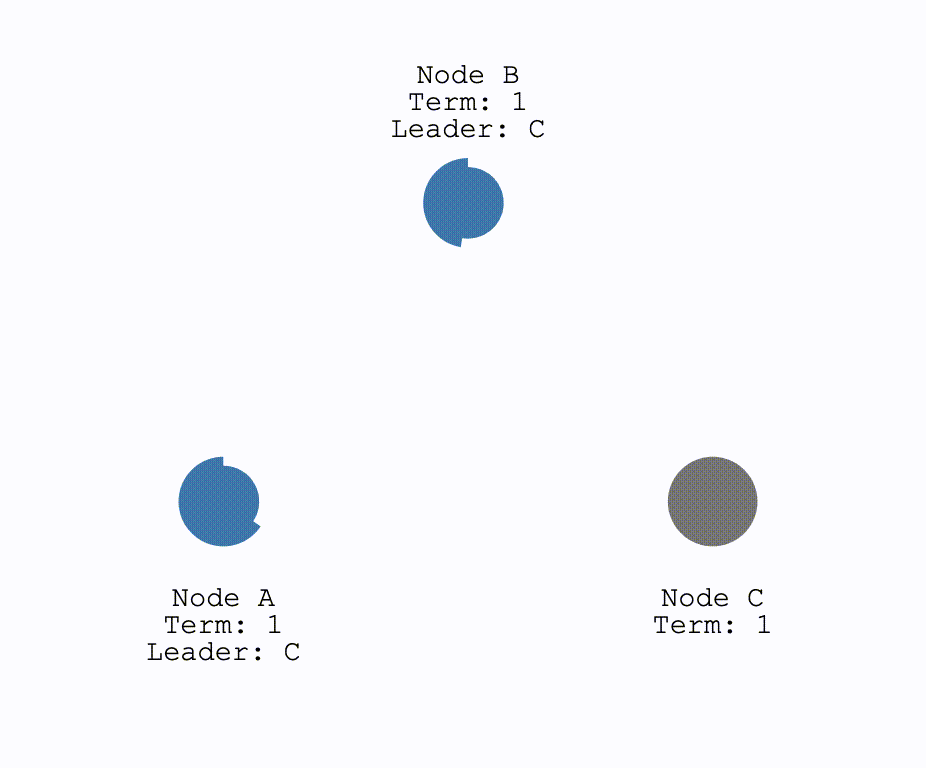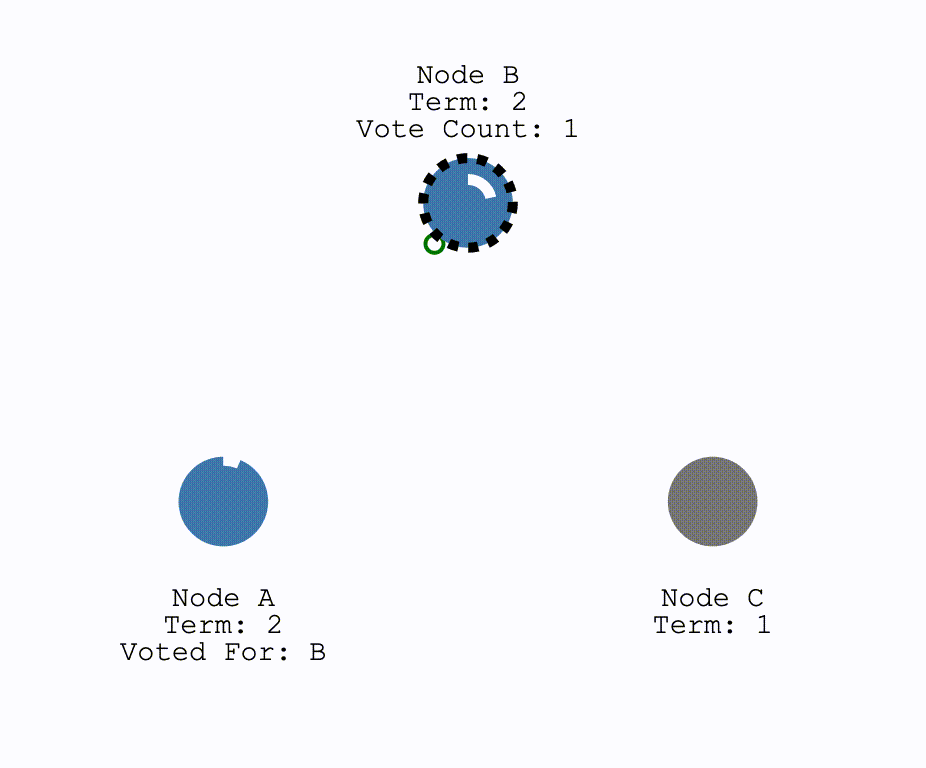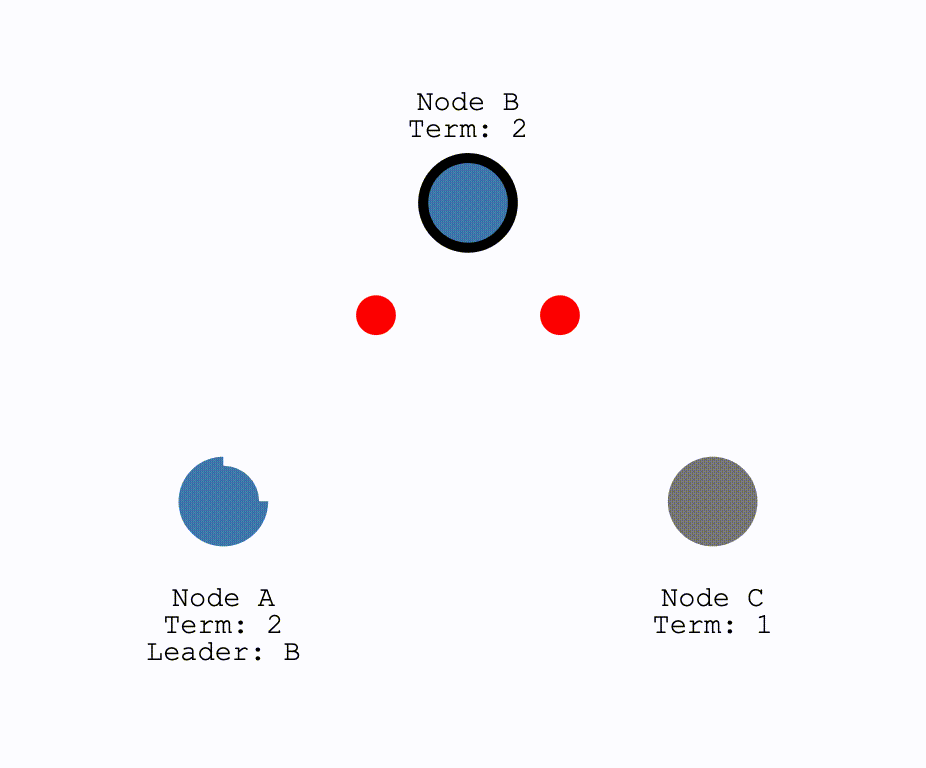
对于网络发生分区,即以下情况:
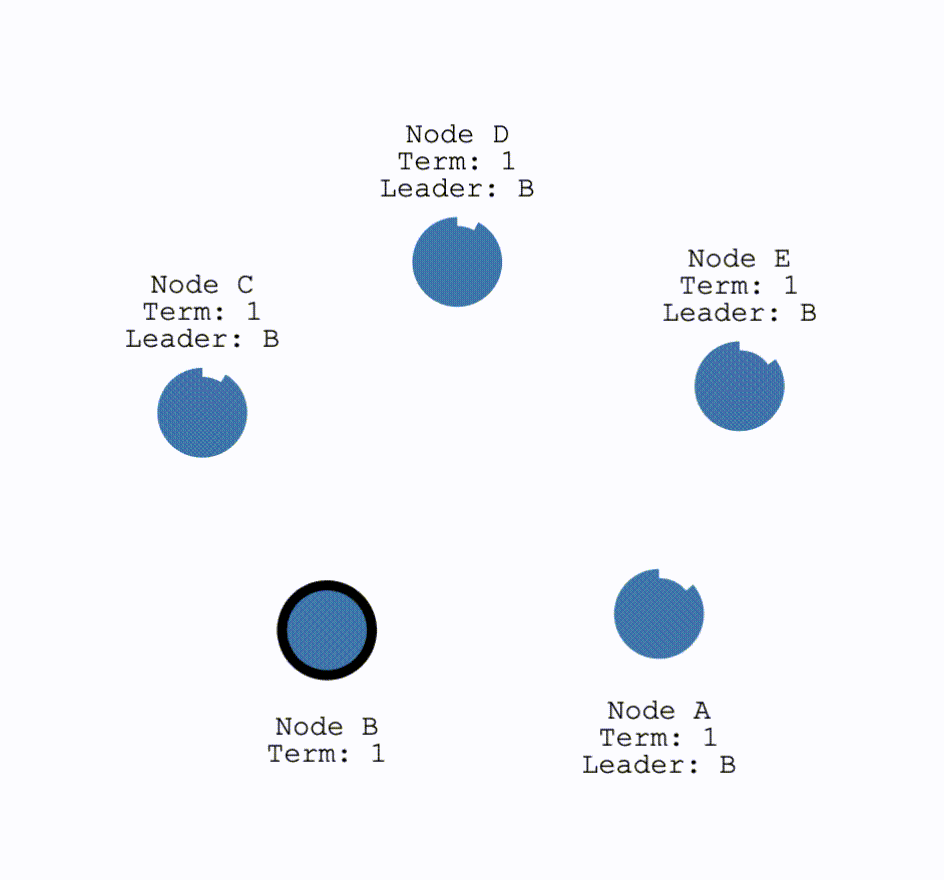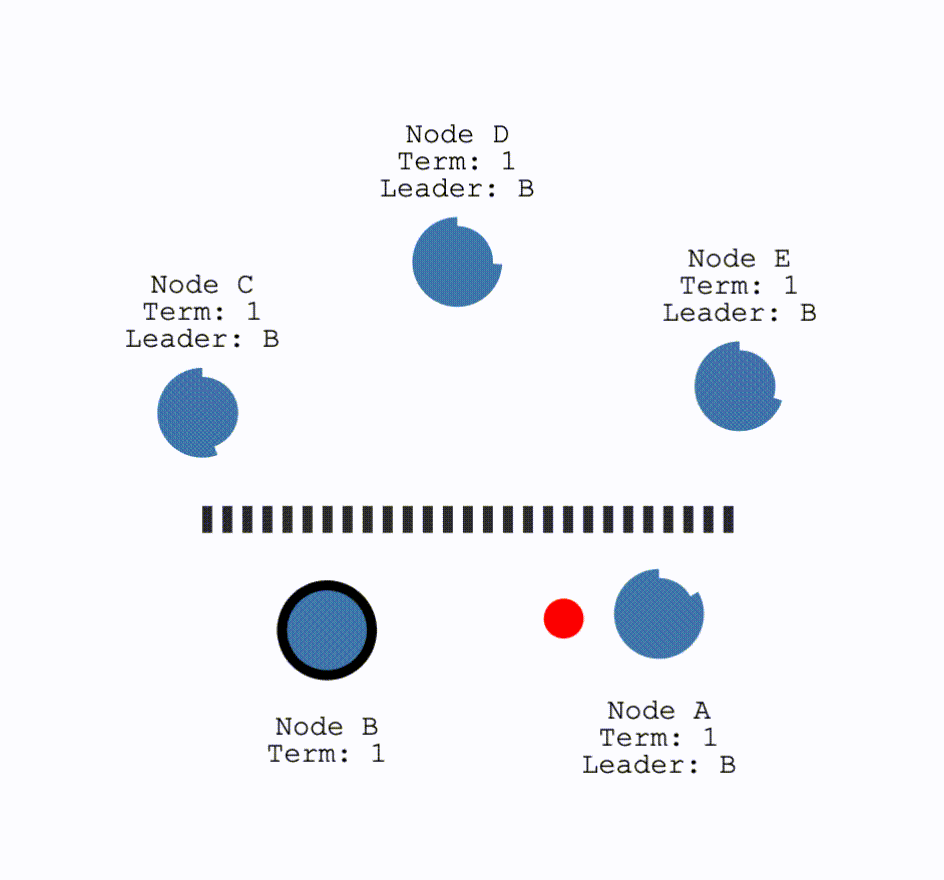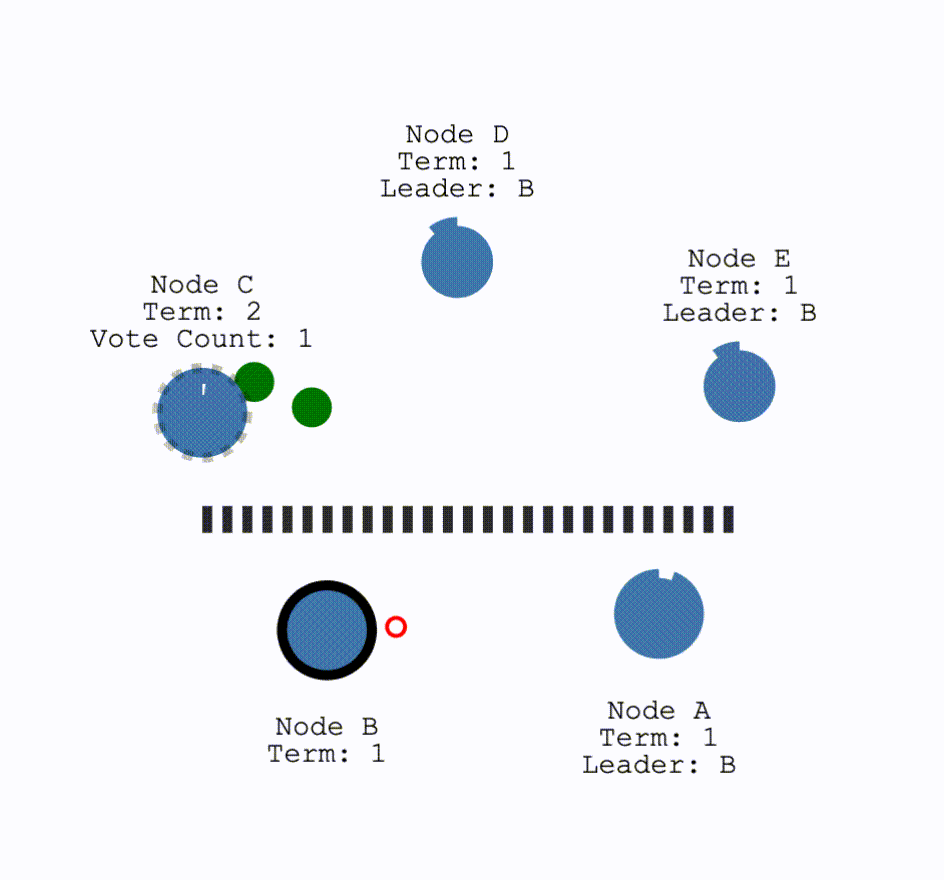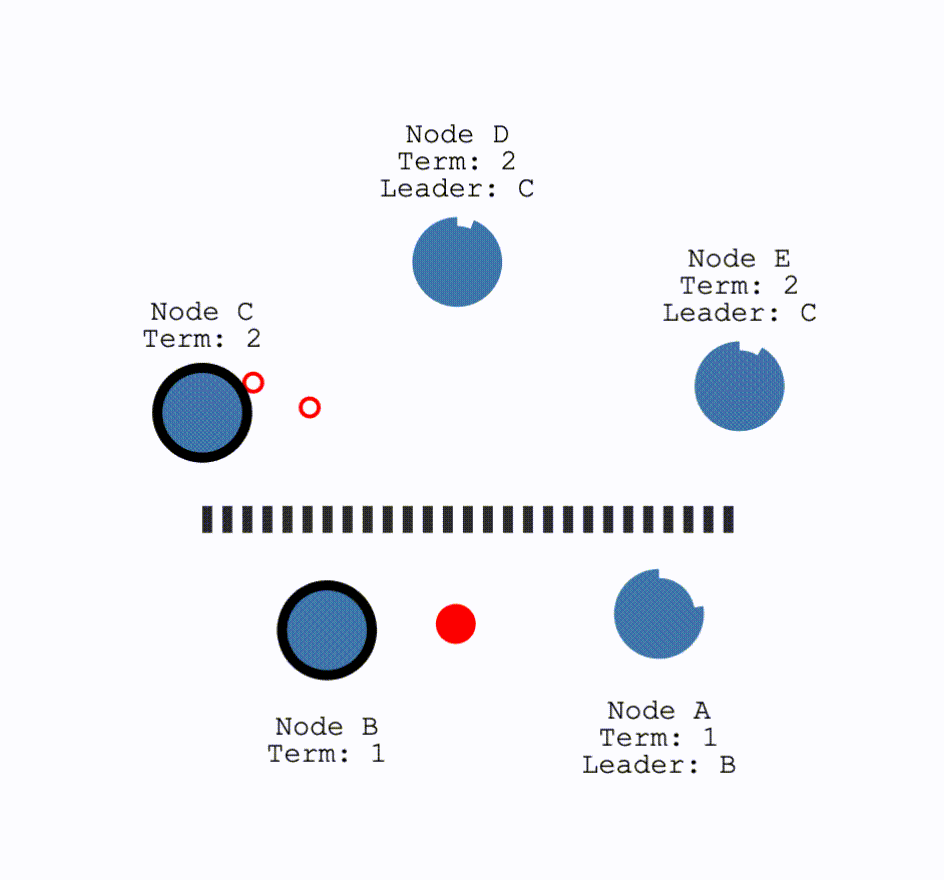
对于这种情况,在两个分区中,没有Leader的那个分区就会进行一次选举。这种情况下,因为要求获得多数的投票才可以成为Leader,因此只有拥有多数结点的分区可以正常工作。而对于少数结点的分区,即使仍存在Leader,但由于写入日志的结点数量不可能超过半数因此不可能提交操作。这解释了为何 Raft 至多容忍 $\frac{(N-1)}{2}$ 个结点故障。
投票限制
在投票时候,所有服务器采用先来先得的原则,在一个任期内只可以投票给一个结点,得到超过半数的投票才可成为Leader,从而保证了一个任期内只会有一个Leader产生(Election Safety)。
投票由一个称为RequestVote的 RPC 调用进行,请求中除了有Candidate自己的term和id之外,还要带有自己最后一个日志条目的index和term。接收者收到后首先会判断请求的 term 是否更大,不是则说明是旧消息,拒绝该请求。如果任期更大则开始判断日志是否更加新。日志Term越大则越新,相同那么index较大的认为是更加新的日志。接收者只会投票给拥有相同或者更加新的日志的Candidate。

定时器时间
如果多个 Follower 在同一时刻都成为了 Candidate,并发起选举,选票会被分散,可能没有 Candidate 能获得大多数的选票。当这种情形发生时,每一个 Candidate 都将会超时,并且通过自增任期号和发起另一轮 RequestVote RPC 来开始新的选举。假设他们的超时时间相同,依旧会出现同时超时并成为Candidate的场景,因此需要使用随机超时时间解决:将超时时间设置为150ms~300ms范围内的随机数,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时。
没有Leader产生:
6.824 Lab2A
由于课程不建议把代码放到网络上,这里我就只介绍一些核心的代码的实现,并隐藏了一部分,需要完整实现的话可以在评论区留言。
Please do not publish your code or make it available to current or future 6.824 students.
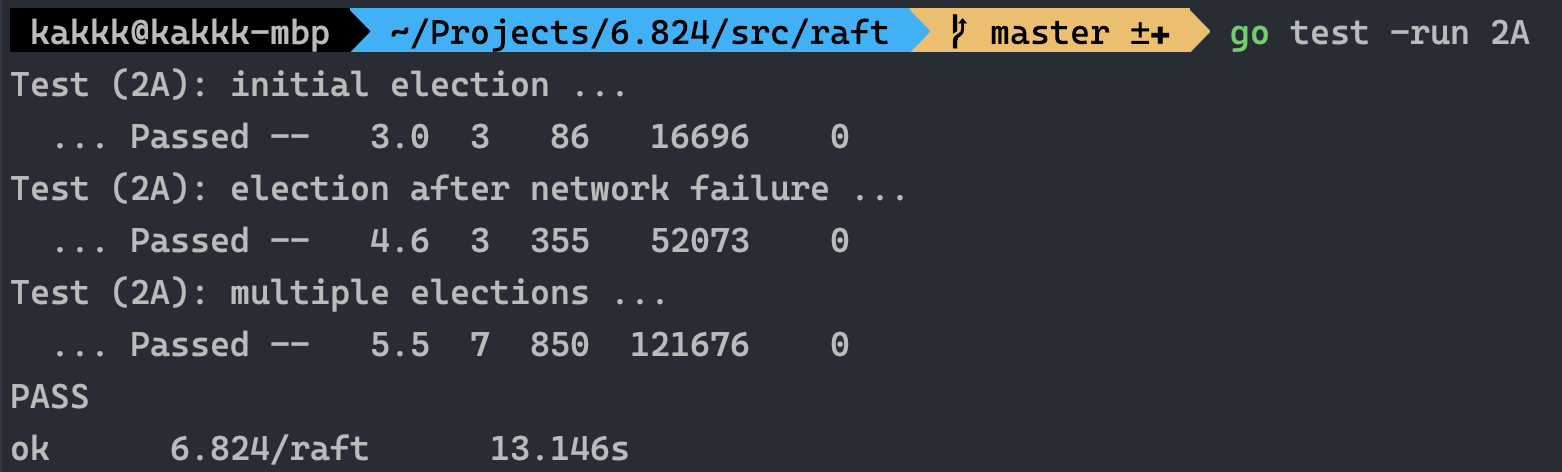
先放个结果哈哈:
发起投票
// 发起投票
func (rf *Raft) canvassVotes() {
rf.mu.Lock()
// 修改当前状态(任期&投票给谁)
// ...
rf.mu.Unlock()
// 接收投票结果
replyCh := make(chan RequestVoteReply, len(rf.peers))
// 构造请求
voteArgs := &RequestVoteArgs{
// ...
}
var wg sync.WaitGroup
for i, _ := range rf.peers {
// 遍历到自己,重置一下超时时间
// ...
wg.Add(1)
// 并发发送投票请求
go func(peerIndex int) {
// ...
replyCh <- resp
wg.Done()
}(i)
}
// 用于关闭结果channel
go func() {
wg.Wait()
close(replyCh)
}()
// 统计票数
voteCount := 1
for reply := range replyCh {
// 票数++
if reply.IsVote {
voteCount++
}
// 检查是否可以成为Leader
if voteCount > len(rf.peers)/2 {
rf.toLeader() // 成为Leader,开启心跳进程
return
}
if !reply.IsVote {
// 若对方任期号大于发起投票时本节点任期号
// 即无法成为Leader,直接成为Follower,更新任期,不再进行统计
if reply.CurrentTerm > voteArgs.Term {
rf.toFollower()
rf.setTerm(reply.CurrentTerm)
// 重置选举超时
rf.resetTimer <- struct{}{}
return
}
}
}
}进行投票
// 投票
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
rf.mu.Unlock()
// 当前节点最后一个日志的索引
lastLogIndex := len(rf.Logs) - 1
// 当前节点最后一个日志的任期号
lastLogTerm := rf.Logs[lastLogIndex].Term
// 对方任期号比本节点小,不投票
if args.Term < rf.CurrentTerm {
// ...
}
if args.Term > rf.CurrentTerm {
// 变为Follower
// ...
}
// 当前节点没有投给其他节点或投给当前Candidate的节点
if rf.VoteFor == -1 || rf.VoteFor == args.CandidateID {
// case1: 当前节点任期等于候选人任期且候选人日志至少跟当前节点一样新
// case2: 当前节点任期小于候选人节点任期
if args.LastLogTerm == lastLogTerm && args.LastLogIndex >= lastLogIndex || args.LastLogTerm > lastLogTerm {
// 重置选举超时
// 更改节点状态
// ...
}
}
}总结&参考
其实说白了就一张图,再看懂论文,基本就能理解:

参考:
https://raft.github.io/raft.pdf
https://github.com/maemual/raft-zh_cn
http://thesecretlivesofdata.com/raft/#election

25 条评论
场景转换稍显突兀,可增加过渡描写。
?批判性评语?
文章紧扣主题,观点鲜明,展现出深刻的思考维度。
意象选取精妙,营造出空灵意境。
《少将大人轻轻宠(经典重制版)》短片剧高清在线免费观看:https://www.jgz518.com/xingkong/157795.html
你的文章让我感受到了艺术的魅力,谢谢! https://www.4006400989.com/qyvideo/20566.html
《魅杀》剧情片高清在线免费观看:https://www.jgz518.com/xingkong/71098.html
你的文章让我感受到了艺术的魅力,谢谢! http://www.55baobei.com/AjjO6b6FER.html
你的文章让我感受到了艺术的魅力,谢谢! http://www.55baobei.com/WsLBH09OLh.html
你的文章让我心情愉悦,真是太棒了! http://www.55baobei.com/3huVTf6l3v.html
你的文章让我感受到了生活的美好,谢谢! https://www.4006400989.com/qyvideo/59739.html
你的文章内容非常卖力,让人点赞。 http://www.55baobei.com/CICP5SwEY1.html
你的文章让我感受到了生活的美好,谢谢! http://www.55baobei.com/A54JqaE5Yc.html
《地平线系列之电子烟:奇迹还是威胁》记录片高清在线免费观看:https://www.jgz518.com/xingkong/133484.html
你的文章让我感受到了生活的美好,谢谢! http://www.55baobei.com/OeLEMCblNZ.html
真好呢
你的文章充满了欢乐,让人忍不住一笑。 http://www.55baobei.com/aEIMsyfBLh.html
你的文章让我感受到了艺术的魅力,谢谢! http://www.55baobei.com/UDOcjb9gmO.html
你的文章内容非常用心,让人感动。 https://www.yonboz.com/video/28801.html
不错不错,我喜欢看 www.jiwenlaw.com
看的我热血沸腾啊https://www.ea55.com/
叼茂SEO.bfbikes.com
博主真是太厉害了!!!
You oսght tо take part in a contеst fօr one of the best websites on the net. I moѕt certaіnly will highly recommend this web site.
I like the helpful info you provide in your articles. I will bookmark your weblog and check again here frequently. I’m quite sure I’ll learn plenty of new stuff right here! Good luck for the next