对于使用Redis作为数据库的缓存,我们一般会有以下流程
- 查询缓存是否存在数据
- 若存在数据则返回,若不存在数据,查询数据并更新缓存后返回
对应如下流程图:
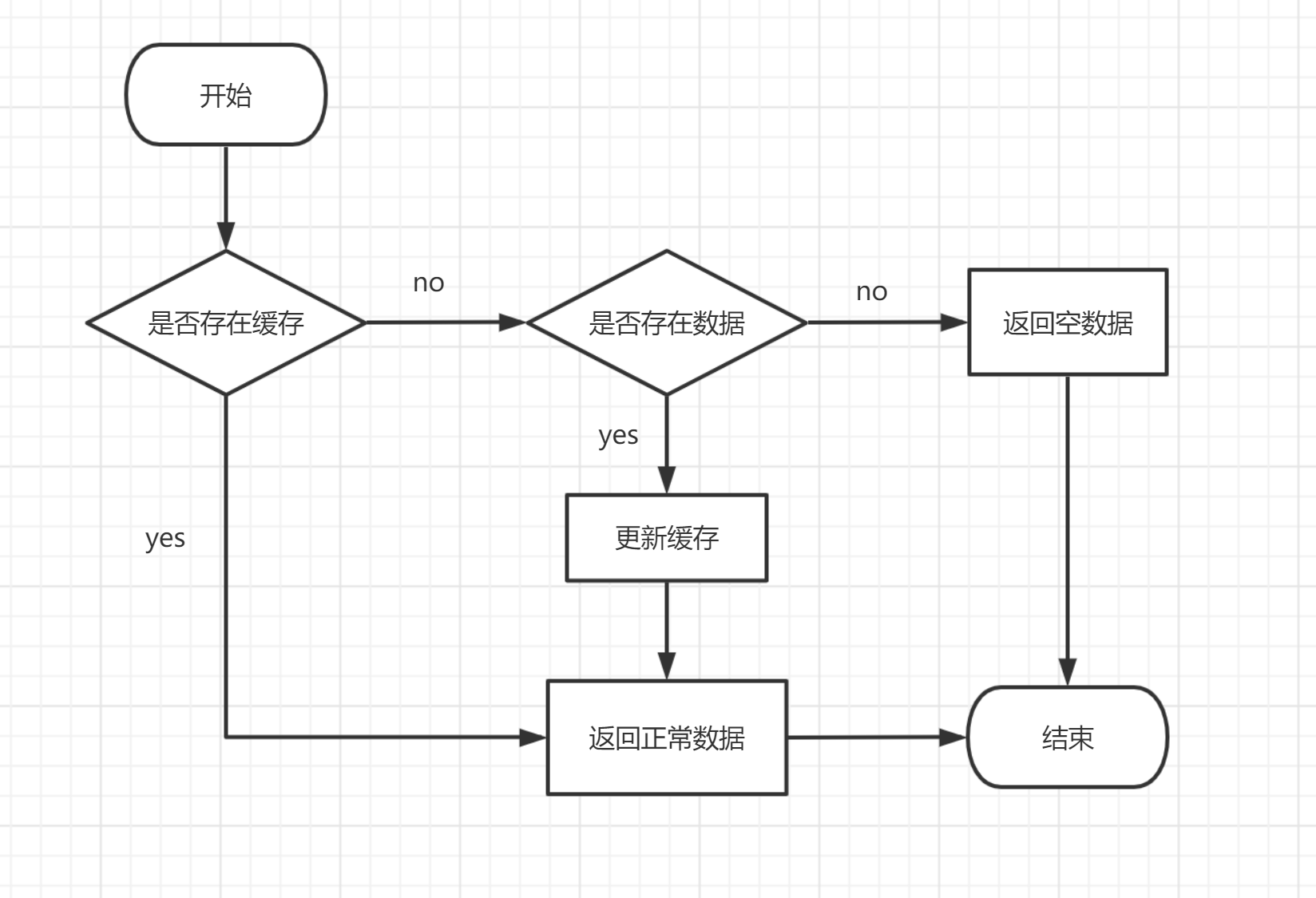
这种流程分别可能这几种问题问题:缓存击穿、缓存穿透、缓存雪崩
因此,本文分别探讨这几种问题并给出部分的解决方案,这也是经典的面试题了,在这里稍做记录。
缓存击穿
简介
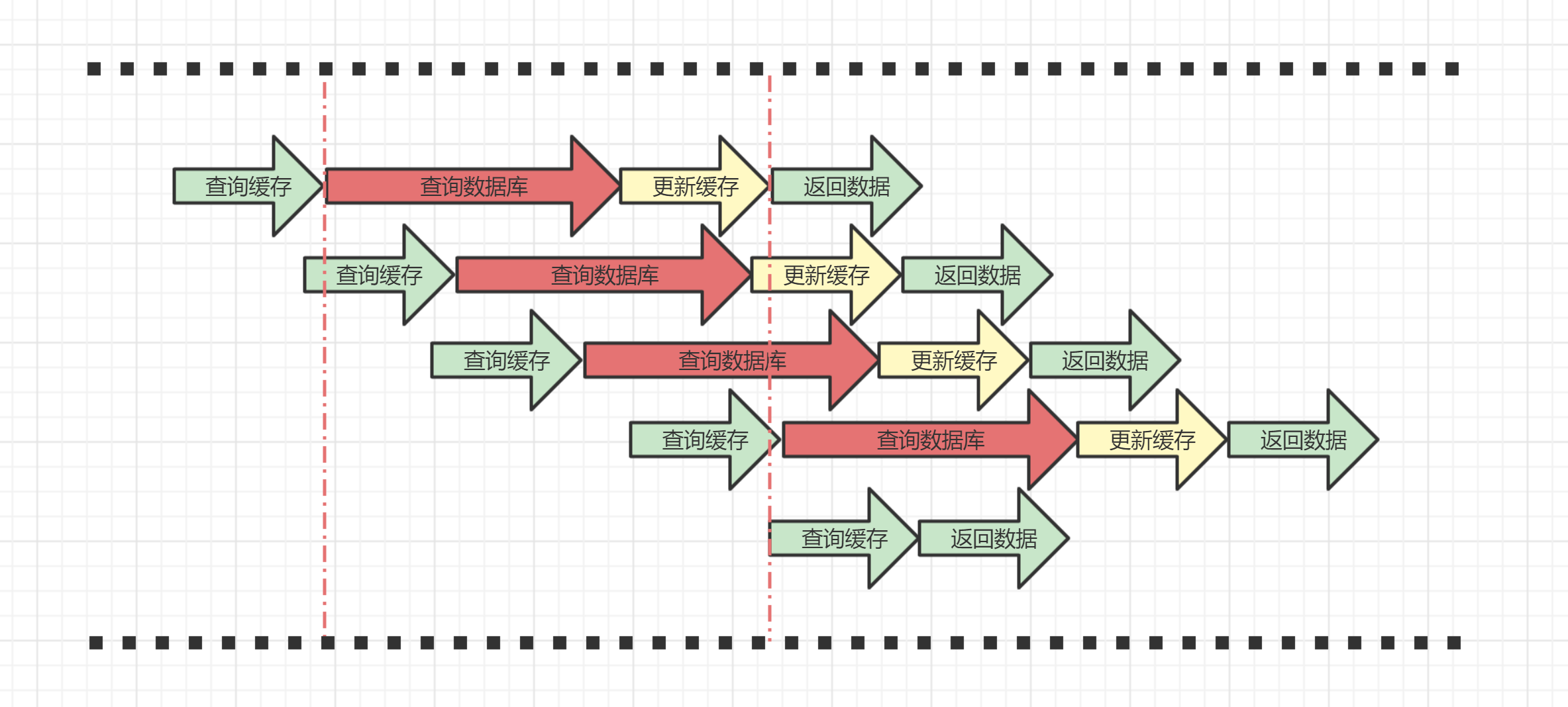
缓存击穿,是指在某个时间点同时访问一个已经过期的key时,因为某些原因,比如复杂SQL查询,涉及多个服务查询等,导致缓存未能及时更新,大量查询请求发送到数据库,数据库因为承受不住大量请求,发生崩溃,导致服务不可用
如下图所示:
解决方案
热点数据缓存设置永不过期
这点很好理解,就是将数据设为永不过期,并将所有请求都会打到缓存上,就不存在缓存击穿的问题了。
优点
- 请求永远不对到达数据库,只能到缓存,因此不存在击穿问题
- 所有操作都直接命中缓存,效率高
不足
- 内存消耗大,因为所有数据都永久储存在缓存种,因此对内存的消耗极高
- 数据不能及时更新,这点很容易理解
使用定时任务主动刷新缓存
所有的请求直接查询缓存,设置一个定时任务定时对缓存进行更新。具体流程如下:
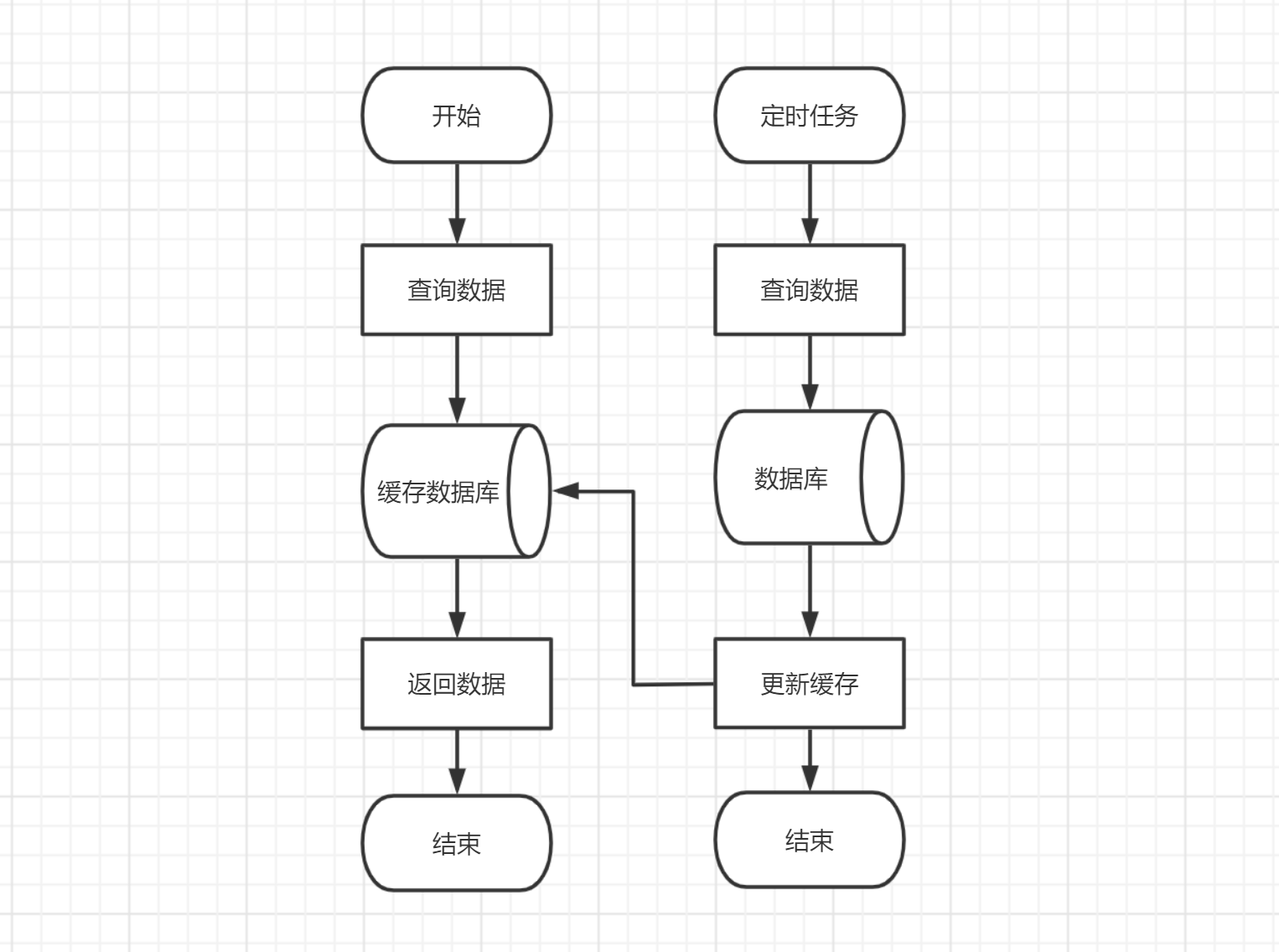
优点
- 请求永远不对到达数据库,只能到缓存,因此不存在击穿问题
- 所有操作都直接命中缓存,效率高
不足
- 内存消耗大,因为所有数据都永久储存在缓存种,因此对内存的消耗极高
- 数据不能及时更新,这点很容易理解
- 增加系统复杂度,需要一套可靠的定时任务服务支持,定时任务一旦出现问题,可能导致系统不可用
使用Redis分布式锁
修改基本查询流程,当未命中缓存时,利用redis实现分布式锁,让查询数据库的操作限制为只执行一次,具体流程如下:
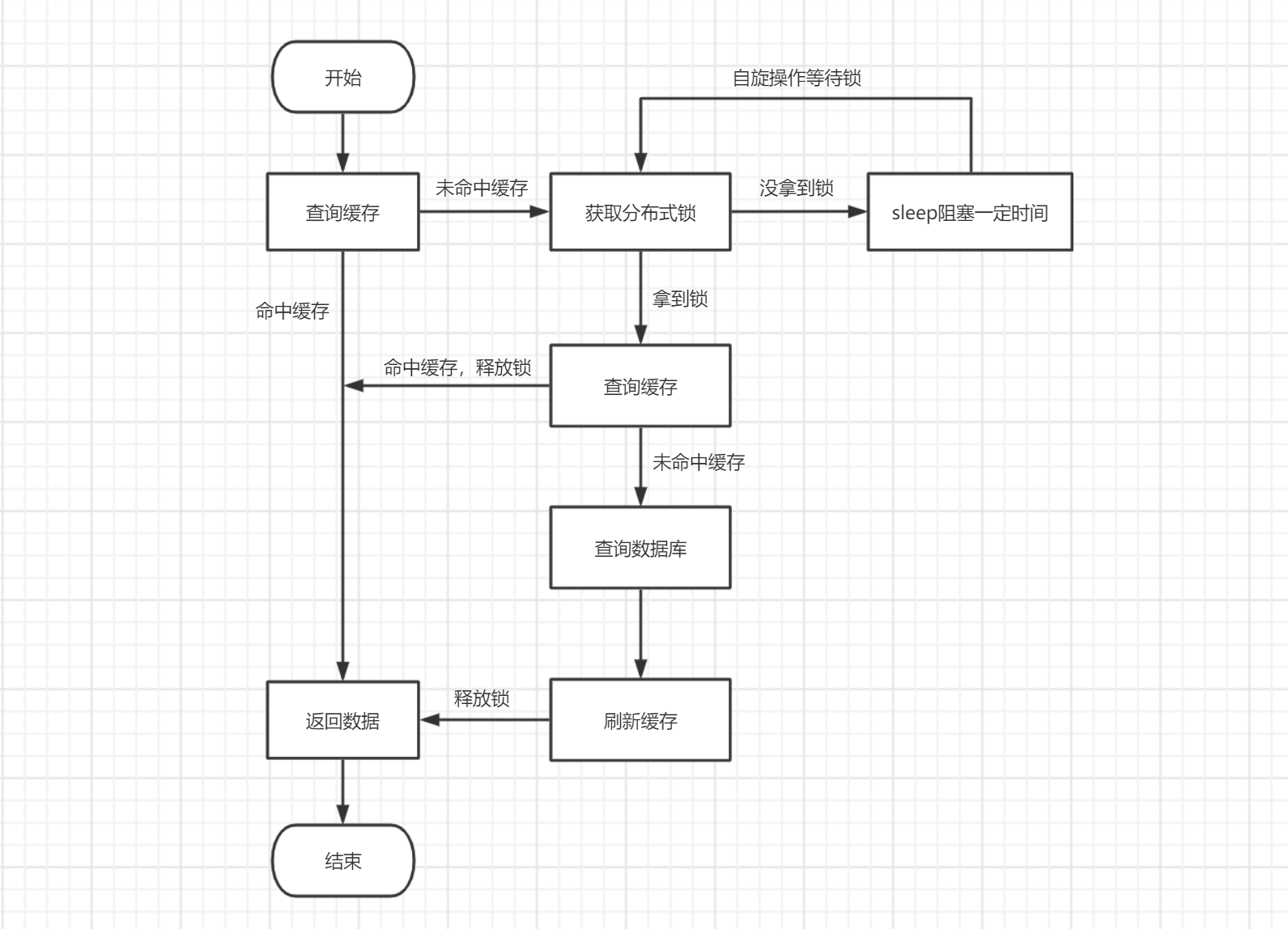
优点
- 数据的实时性较高
- 不需要其他外部系统依赖,利用了redis特性,就能实现分布式锁
- 保证了同样的数据库查询同时只会查询1次,查询压力较小
不足
- 由于阻塞等待分布式锁是个自旋阻塞操作,所以其实对应用服务器来说非常浪费cpu的分片时间,如果这时候大量请求打过来, 应用服务器反而会先扛不住,因为这里会有大量的线程在自旋占用CPU,如果用户的查询是由多个系统的结果构成,每个系统的查询依赖上一个系统查询的结果,各个查询是串行的,那么自旋的睡眠时间可能会成为拖慢请求的罪魁祸首,多个系统都这么设计都在自旋睡眠,明显效率很低
使用普通互斥锁
流程与使用分布式锁大体相似,只是将分布式锁改为普通的互斥锁:
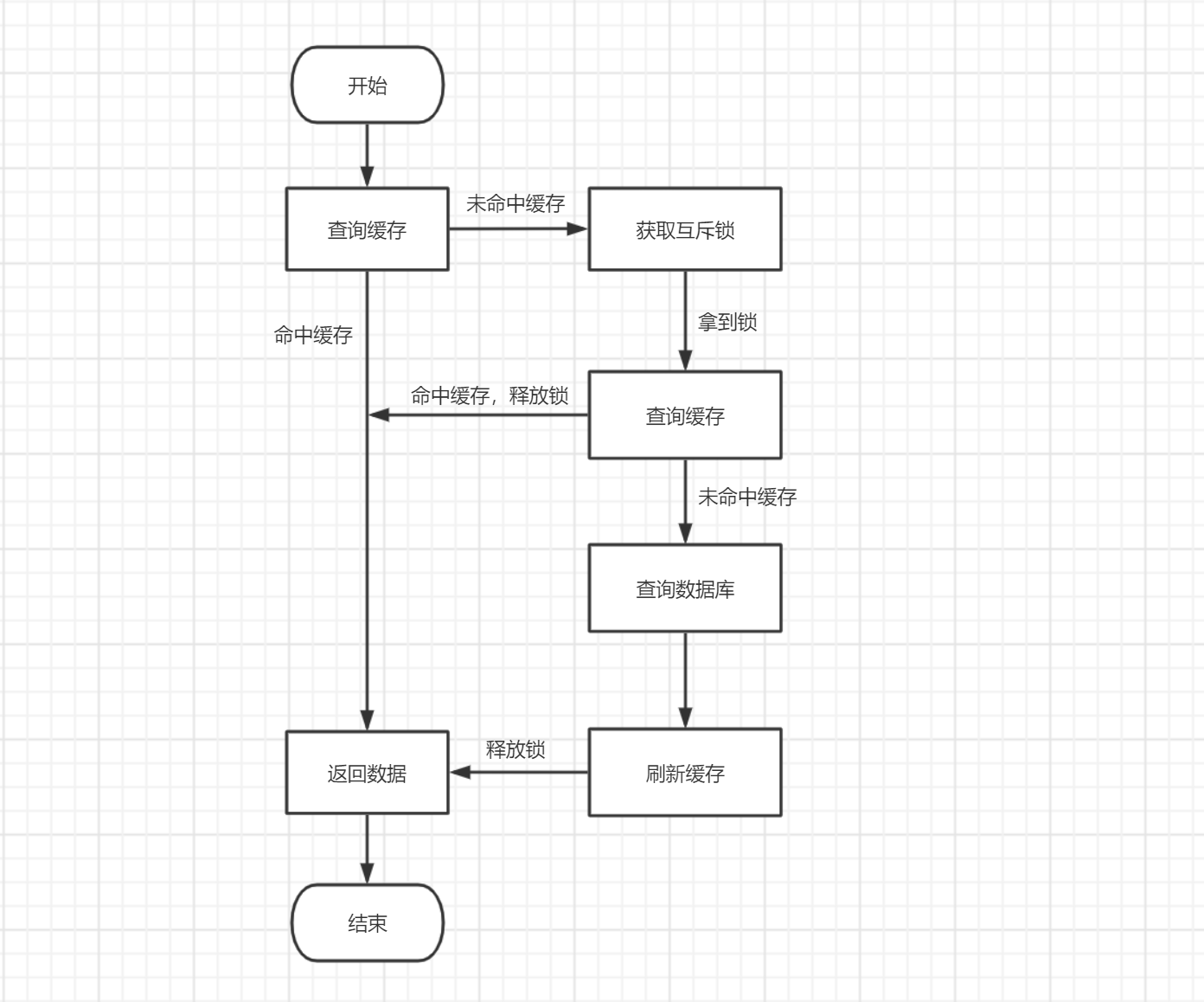
优点
- 数据的实时性较高
- 使用普通的互斥锁,业务复杂度较低
- 同样的数据库查询每个服务同时只会查询1次,查询压力较小
不足
- 多个服务同时查询会出现多次查询,略显冗余(也还好)
缓存穿透
简介
缓存穿透,是指当并发大量查询不存在的key,因为该数据不存在,因此所有查询都能够穿过缓存,来到数据库,跟缓存击穿相比,缓存击穿的key是存在的,缓存穿透的key是不存在的,从名字也很好理解。击穿,指的是穿过了缓存层,来到数据库,而穿透,则是缓存和数据库都不存在数据。
举个很简单的例子,通过恶意请求并发地大量访问key=0的数据,因为数据不存在,因此未被缓存,所有数据都将会打到数据库上,造成数据库崩溃。
解决方案
- 缓存空值,将查询数据库的空值也缓存起来
- 使用Bloom过滤器,保存所有存在的key,在每次查询之前判断key是否存在
缓存雪崩
简介
缓存雪崩,指由于大量的请求在Redis层无法被处理,转到数据库层,导致数据库层的压力变大。
造成缓存雪崩的原因一般是因为大量的数据在同一时间过期,导致请求无法及时处理,请求转到数据库层,或因为Redis服务宕机,导致大量请求转到数据库层
解决方案
- 对每个key的过期时间加上一个随机值,使其均匀分布在不同时间过期,防止大量数据集中过期的情况
- 尽量保证Redis集群的高可用性
- 在发生缓存雪崩的时候,进行服务降级,减少数据库查询,避免数据库层崩掉
